
Gu(2020)在The Review of Financial Studies发表的Empirical Asset Pricing via Machine Learning中,详细实证了机器学习模型在美股市场的表现。根据结果得出,机器学习改善了对预期收益的预测,当应用于投资组合构建时,性能的改善在更复杂的模型中表现得最显著,这在很大程度上是由于机器学习模型考虑到了因子间的非线性关系,而这些非线性关系是简单的方法所忽略的。
A股市场作为新兴市场,很多特征与发达市场有着明显的区别,主要有以下三点:
基于以上的市场特征,并参考Gu(2020),作者主要探讨了机器学习的多因子模型在A股市场上的表现能否达到预期效果?哪些因子模型在A股市场上表现更优?不同的股票(国有/非国有,大盘/小盘等)是否有明显的区别?
本文使用了2000年1月至2020年6月的A股数据,并使用1年期国债利率作为无风险利率。一共使用了94个股票因子,11个宏观因子(具体见附注)。94个股票因子中,其中最后4个因子是描述股票是否属于某一类的哑变量因子,比如是否是国有控股公司(是为1,否为0)。最终输入到模型的因子数量是1160个,这中间还包括90个股因子(连续变量),90个股因子与11个宏观因子的乘积(90*11=990个),以及80个哑变量因子(包括行业分类等)共计1160个因子。
初始训练时间为2000-2008,验证集为2009-2011,测试集2012-2020。每次训练都用上一个月末的因子去预测股票下一个月的收益,验证集大多数都用在超参数优化。连续变量的因子在模型中以截面的Rank值作为输入。本文使用了以下模型,模型滚动训练,每一年重新训练一次。

样本外的预测要采用R方做评估,即样本外预测收益与实际收益的拟合度,如下式表示:
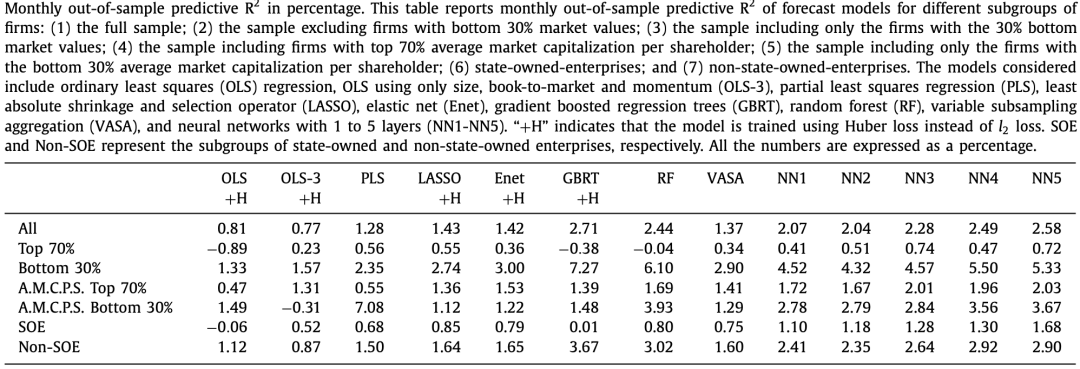
下表给出了所有模型在不同样本空间的R方表现,主要有以下几个发现,全样本(All)测试中的模型表现说明:
OLS模型的R方为0.81%,说明OLS还是有一定的预测能力。仅使用三个因子的OLS-3表现不如OLS,说明Size/BP/Momentum不足以构建预测模型。
基于OLS的增强模型PLS/LASSO/Enet的R方均大于1%,RF/GBRT两个树模型和NN1-NN5五个深度神经网络模型的R方都超过2%, 说明模型复杂度的提升带来了预测效果的提升。
A股全样本测试的结果,特别是GBRT的效果要比美国市场的表现好的多。这原因是A股市场的特殊结构导致的。接下来分别从以下角度作对比测试:大盘股(Top 70%)与小盘股(Bottom 30%)、大股东股票(指股东平均持有股市值前70%的公司,表中用A.M.C.P.S Top 70%表示)与小股东股票(表中用A.M.C.P.S Bottom 30%表示)及国有控股股票与非国有控股股票。
PLS、RF及NN模型在小股东股票的表现更优。 OLS-3在小股东股票样本中比在大股东股票样本中表现更差,这在某种程度上预示着传统的三因子模型可能不适用于中国的小股东股票。
预测国有企业的收益需要一种高度灵活的方法,能够更有效解释非线性效应。这种额外的复杂性可能是必要的,因为国有企业由国家控制,有两个主要目标:创造利润和执行国家政策。然而,我们的研究结果与早期的研究结果形成了对比,这些研究认为,由于中国国有企业的财务不透明和股价的低信息化,预测其股票收益并不容易。
树模型和神经网络,在中国股市的样本外R方表现令人满意。此外,我们的分析揭示了中国股市不同于Gu等人(2020)研究的美国市场的两个重要特征。首先,几乎所有模型都能更好地预测中国市场上小股(非国企)股票的月收益,而不是大股(国企)股票。其次,神经网络可以跨不同的子样本提供健壮的性能。
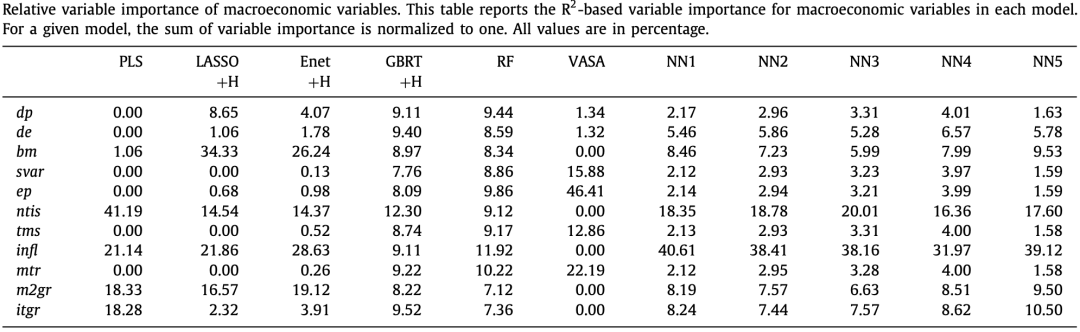
我们一共使用了94个股因子和11个宏观因子,采用以下方法测试因子在模型中的贡献度:将目标因子的值全部设定为0,并计算模型R方的下降程度,以此判断该因子对于模型的重要程度。下表是11个宏观因子在各模型中的重要程度。
总体而言,我们得知infl和ntis是预测中国股市月收益的两个最具影响力的宏观经济变量,尤其是神经网络。另一方面,股息价格比率(dp)、市场波动率(svar)、每股总收益(ep)、期限息差(tms)和市场流动性(mtr)不那么重要,因为它们被大多数模型忽略了。
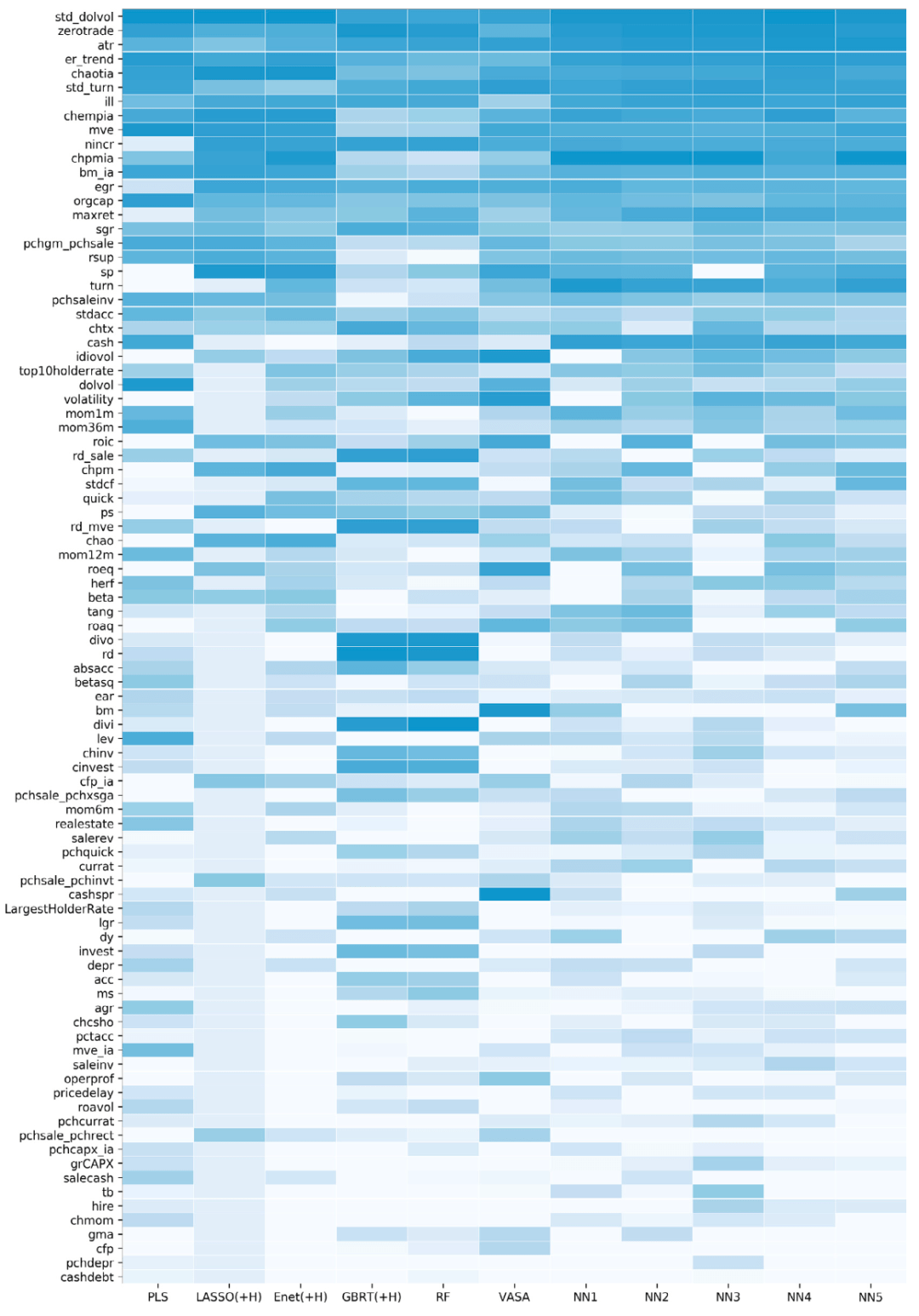
下图给出了90多个个股因子在各模型中的重要度(颜色越深越重要),我们发现:
我们发现与市场流动性相关的股票特征在预测中国股市时最有用,如流动性波动率(std_dolvol和std_turn)、零交易天数(zerotrade)和非流动性测度(ill)是最显著的预测因子。
第二组有一定的影响力的因子包括基本面因子及估值比率,如行业调整后的资产周转率变化(chaotia)、行业调整后的员工变化(chempia)、总市值(mve)、近期盈利增长数(nincr)、行业调整后的利润率变化(chpmia)和行业调整后的账面市值比(bm_ia)。
第三组由风险指标组成,包括特殊收益波动率(idiovol),总收益波动率(volatility)和市场beta (beta)。
我们还观察到,神经网络模型(NN1-NN5)、正则化线性模型(PLS、LASSO、Enet)和VASA倾向于选择一组类似的因子。
树模型,包括GBRT和RF,比其他模型倾向于选择更广泛的特征集,这也在Gu等人(2020)中观察到。同样,流动性变量和基本面因子是GBRT和RF最重要的两组预测因子。
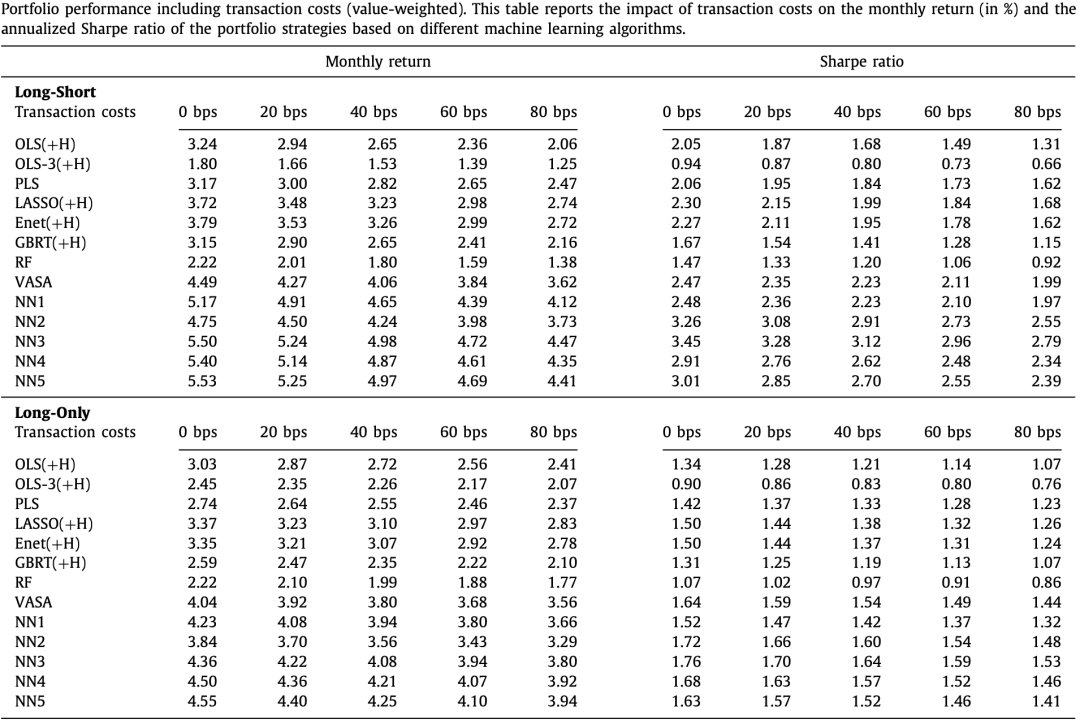
下表给出了月度分10组调仓,多空和纯多的收益统计及累计收益曲线(费前收益),我们在图5和表6中的结果证实了Gu等人(2020)的发现,即神经网络优于他们研究中考虑的所有其他模型。对于多空组合,我们得到的中国股市的夏普比率远高于Gu等人(2020)发现的美国股市的夏普比率。例如,NN3在中国市场上给出的最高夏普比率(SR= 3.45)是NN4产生的最佳夏普比率(SR= 1.35)的两倍多。如上所述,由于交易限制,多空策略几乎不可行,因此我们在解释这些结果时很谨慎。同时,只做多的投资组合夏普比率最高为1.76,仍高于美国市场的多空策略。鉴于这种高水平,在更现实的假设下评估只做多的投资组合的表现至关重要。
在表10中,我们报告了包括不同交易成本水平时的月收益和夏普比率。事实上,由于我们的策略使用频率较低,这些投资组合仍然提供了可观的、经济上显著的表现。对我们的基准策略NN4,当我们假设往返成本为80个基点时,在极端情况下,多空设置中的夏普比率从2.91下降到2.34。使用更现实的20个基点的假设,夏普比率仅下降到2.76。对于只做多策略也能得出类似的观察结果,从实践者的角度来看,这更相关。对于只做多策略,在假设80个基点的情况下,夏普比率从1.68下降到1.46。因此,我们的交易成本分析表明,即使在交易成本规模的保守假设下,不同策略的表现仍然具有经济意义。
本文研究了几种机器学习方法对中国股市的预测能力。我们得知,最关键的因子是基于流动性的因子。让我们惊讶的是,基于趋势的因子只发挥了次要作用。我们的结果还表明,基本面因子是第二大最关键的因子类别。我们还发现,散户投资者的短期主义在短期投资范围内产生了可观的可预测性,特别是对小股。与此同时,由于政府信号在中国市场扮演着如此重要的角色,我们观察到国有企业在较长时期内的可预测性大幅提高。
我们的投资组合分析表明,短期内的高可预测性转化为多空投资组合的高夏普比率。特别是神经网络和VASA在2015年中国股市暴跌期间也提供了强劲的表现。然而,在中国市场做空股票是不现实的。因此,我们也分析了只做多的组合,发现业绩仍然具有经济意义。

