
原标题:入门 从概念到案例:初学者须知的十大机器学习算法 选自kdnuggets 作者:Reen
本文先为初学者介绍了必知的十大机器学习(ML)算法,并且我们通过一些图解和实例生动地解释这些基本机器学习的概念。我们大家都希望本文能为理解机器学习基本算法提供简单易读的入门概念。
在《哈佛商业评论》发表「数据科学家是 21 世纪最性感的职业」之后,机器学习的研究广受关注。所以,对于初入机器学习领域的学习者,我们放出来一篇颇受欢迎的博文——《初学者必知的十大机器学习算法》,尽管这只是针对初学者的。
机器学习算法就是在没有人类干预的情况下,从数据中学习,并在经验中改善的一种方法,学习任务可能包括学习从输入映射到输出的函数,学习无标签数据的隐含结构;或者是「基于实例的学习」,通过与存储在记忆中的训练数据做比较,给一个新实例生成一个类别标签。基于实例的学习(instance-based learning)不会从具体实例中生成抽象结果。
可以这样来描述监督学习:使用有标签的训练数据去学习从输入变量(X)到输出变量(Y)的映射函数。
a. 分类:通过一个给定的输入预测一个输出,这里的输出变量以类别的形式展示。例如男女性别、疾病和健康。
b. 回归:也是通过一个给定的输入预测一个输出,这里的输出变量以实数的形式展示。例如预测降雨量、人的身高等实数值。
本文介绍的前 5 个算法就属于监督学习:线性回归、Logistic 回归、CART、朴素贝叶斯和 KNN。
集成学习也是一种监督学习方法。它意味着结合多种不同的弱学习模型来预测一个新样本。本文介绍的第 9、10 两种算法--随机森林 Bagging 和 AdaBoost 提升算法就是集成学习技术。
非监督学习问提仅仅处理输入变量(X),但不会处理对应的输出(也就是说,没标签)。它使用无标签的训练数据建模数据的潜在结构。
a. 关联:就是去发觉在同一个数据集合中不同条目同时发生的概率。广泛地用于市场篮子分析。例如:如果一位顾客买了面包,那么他有 80% 的可能性购买鸡蛋。
c. 降维:顾名思义,降维就是减少数据集变量,同时要保证重要信息不丢失。降维能够最终靠使用特征提取和特征选择方法来完成。特征选择方法会选择原始变量的一个子集。特征提取完成了从高维空间到低维空间的数据变换。例如,主成分分析(PCA)就是一个特征提取方法。
本文介绍的算法 6-8 都是非监督学习的例子:包括 Apriori 算法、K-均值聚类、主成分分析(PCA)。
强化学习是这样一种学习方法,它允许智能体通过学习最大化奖励的行为,并基于当前状态决定下一步要采取的最佳行动。
强化学习一般是通过试错学习到最佳行动。强化学习应用于机器人,机器人在碰到障碍物质之后会收到消极反馈,它通过这一些消极反馈来学会避免碰撞;也用在视频游戏中,通过试错发现能够极大增长玩家回报的一系列动作。智能体能够正常的使用这些回报来理解游戏中的最佳状态,并选择下一步的行动。
在机器学习中,我们用输入变量 x 来决定输出变量 y。输入变量和输出变量之间有一个关系。机器学习的目标就是去定量地描述这种关系。
在线性回归中,输入变量 x 和输出变量 y 的关系可以用一个方程的形式表达出来:y=ax+b。所以,线性回归的目标就是寻找参数 a 和 b 的值。这里,a 是直线的斜率,b 是直线 将一个数据集中的 x 和 y 用图像表示出来了。如图所示,这里的目标就是去寻找一条离大多数点最近的一条直线。这就是去减小一个数据点的 y 值和直线.Logistic 回归
线性回归预测是连续值(如厘米级的降雨量),logistic 回归预测是使用了一种变换函数之后得到的离散值(如一位学生是否通过了考试)。
Logistic 回归最适合于二元分类问题(在一个数据集中,y=0 或者 1,1 代表默认类。例如:在预测某个事件是否会发生的时候,发生就是 1。在预测某个人是否患病时,患病就是 1)。这个算法是拿它所使用的变换函数命名的,这个函数称为 logistics 函数(logistics function,h(x)= 1/ (1 + e^x)),它的图像是一个 S 形曲线。
在 logistic 回归中,输出是默认类别的概率(不像线性回归一样,输出是直接生成的)。因为是概率,所以输出的值域是 [0,1]。输出值 y 是通过输入值 x 的对数变换 h(x)= 1/ (1 + e^ -x) 得到的。然后使用一个阈值强制地让输出结果变成一个二元分类问题。
图 2:确定一个肿瘤是恶性的还是良性的回归。如果概率 h(x)0.5,则是恶性的
logistic 回归的目标就是使用训练数据来寻找参数 b0 和 b1 的值,最小化预测结果和实际值的误差。这些参数的评估使用的是最大似然估计的方法。
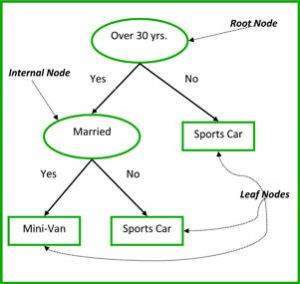
非终端节点(non-terminal node)包含根节点 (root node) 和中间节点 (internal node)。每一个非终端节点代表一个单独的输入变量 x 和这个变量的分支节点;叶节点代表的是输出变量 y。这个模型按照以下的规则来作出预测:
在给定一个早已发生的事件的概率时,我们用贝叶斯定理去计算某个事件将会发生的概率。在给定一些变量的值时,我们也用贝叶斯定理去计算某个结果的概率,也就是说,基于我们的先验知识(d)去计算某个假设(h)为真的概率。计算方式如下:
当给定的一个数据实例时,KNN 算法会在整个数据集中寻找 k 个与其新样本距离最近的,或者 k 个与新样本最相似的,然后,对于回归问题,输出结果的平均值,或者对于分类问题,输出频率最高的类。k 的值是用户自定义的。
Apriori 算法被用来在交易数据库中进行挖掘频繁的子集,然后生成关联规则。常用于市场篮子分析,分析数据库中最常同时出现的交易。通常,如果一个顾客购买了商品 X 之后又购买了商品 Y,那么这个关联规则就可以写为:X - Y。
例如:如果一位顾客购买了牛奶和甜糖,那他有很大的可能性还会购买咖啡粉。这个能写成这样的关联规则: {牛奶,甜糖} - 咖啡粉。关联规则是交叉了支持度(support)和置信度(confidence)的阈值之后产生的。
K-均值是一个对相似的数据来进行聚类的迭代算法。它计算出 k 个聚类的中心点,并给某个类的聚类分配一个与其中心点距离最近的数据点。

c) 计算出每个聚类的中心点。图中的红色、蓝色和绿色的星分别代表三个聚类的中心点。
将每一个数据点重新分配给离它最近的一个聚类中心点。如图所示,上边的五个数据点被分配给了蓝星代表的聚类。按照相同的步骤将数据点分配给红色和绿色星代表的聚类中心点。
计算新聚类的中心点。如图所示,旧中心点是灰色的,新中心点是红色、蓝色和绿色的。
重复步骤 2-3,直至每一个聚类中的点不会被重新分配到另一个聚类中。如果在两个连续的步骤中不再发生明显的变化,那么就退出 K-均值算法。
主成分分析(PCA)通过减少变量的数目来使数据变得更易于探索和可视化。这通过将数据中拥有最大方差的数据抽取到一个被称为「主成分」的新坐标系中。每一个成分都是原始变量的一个新的线性组合,且是两两统计独立的。统计独立意味着这些成分的相关系数是 0。
第一主成分捕获的是数据中最大方差的数据。第二主成分捕获的是剩下的数据中方差最大但是与第一主成分相互独立的数据。相似地,后续的主成分(例如 PC3、PC4)都是剩下的数据中方差最大的但是与之前的主成分保持独立的数据。
图 7:使用主成分分析方法(PCA),三种初始变量(基因)被降为两种新变量
集成意味着通过投票或者取平均值的方式,将多个学习器(分类器)结合起来以改善结果。在分类的时候做投票,在回归的时候求平均值。核心思想就是集成多个学习器以使性能优于单个学习器。有三种集成学习的方法:装袋(Bagging)、提升(Boosting)和堆叠(Stacking)。本文不涉及堆叠。
Bagging:Bagging 的第一步就是在使用 Bootstrap 采样方法得到的数据库中创建多个模型,每个生成的训练集都是原始数据集的子集。每个训练集都有相同的大小,但是有些样本重复出现了很多次,有些样本一次未出现。然后,整个原始数据集被用为测试集。那么,如果原始数据集的大小为 N,则每个生成的训练集的大小也是 N,唯一(没有重复)样本的大小大约是 2*N/3;测试集的大小也是 N。
Bagging 的第二步就是使用同一个算法在不同的数据集上生成多个模型。然后,我们讨论一下随机森林。在决策树中,每个节点都在最好的、能够最小化误差的最佳特征上进行分支,而随机森林与之不同,我们最终选择随机分支的特征来构建最佳的分支。进行随机处理的原因主要在于:即便使用了 Bagging,当决策树选择最佳特征来分支的时候,它们最终会有相似的模型和相关联的预测结果。但是用随机子集上的特征进行分支意味着子树做的预测是没多少相关性的。
a)Bagging 是并行集成,因每个模型都是独立建立的。然而,提升是一个顺序性集成,每个模型都要纠正前面模型的错误分类。
b)Bagging 主要涉及到「简单投票」,每个分类器都投票得到一个最终结果,这个分类结果是由并行模型中的大多数模型做出的;提升则使用「权重投票」。每个分类器都会投票得到一个由大多数模型做出的结果—但是建立这些顺序性模型的时候,给之前误分类样本的模型赋予了较大的权重。
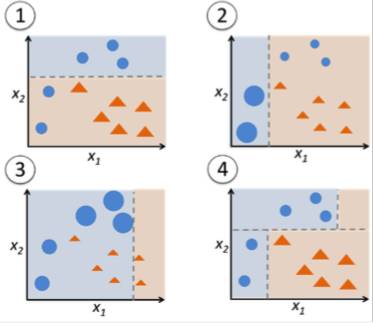
在图 9 中,步骤 1、2、3 指的是被称为决策桩(decision stump)的弱学习器(是一个仅依靠一个输入作出决策的 1 级决策树;是一种根节点直接连接到叶节点的决策树)。构造决策树的过程会一直持续,直到用户定义了一个弱学习器的数目,或者训练的时候再也没任何提升的时候。步骤 4 结合了之前模型中的 3 个决策桩(所以在这个决策树中就有 3 种分支规则)。
数据点的大小说明我们应用了等权重来将它们分为圆形或者三角形。决策桩在图的上半部分用一条水平线来对这些点进行分类。我们大家可以看到,有两个圆被误分为三角形。所以,我们会赋予这两个圆更大的权重,然后使用另一个决策桩(decision stump)。
我们能够正常的看到,之前的步骤中误分类的两个圆要比其余数据点大。现在,第二个决策桩要尝试正确地预测这两个圆。
赋予更大权重的结果就是,这两个圆被左边的竖线正确地分类了。但是这又导致了对上面 3 个小圆的误分类。因此,我们要在另一个决策桩对这三个圆赋予更大的权重。
上一步误分类的 3 个圆要比其他的数据点大。现在,在右边生成了一条竖线,对三角形和圆进行分类。
我们结合了之前 3 步的决策桩,然后发现一个复杂的规则将数据点正确地分类了,性能要优于任何一个弱学习器。
1. 5 种监督学习技术:线性回归、Logistic 回归、CART(分类和决策树)、朴素贝叶斯法和 KNN。
2. 3 种非监督学习技术:Apriori 算法、K-均值聚类、主成分分析(PCA)。
机器学习是(使用样本获取近似函数的)统计学的一个分支。我们有一个确实存在的理论函数或分布用以生成数据,但我们目前不知道它是什么。我们大家可以对这个函数进行抽样,这些样本选自我们的训练集。

