
MyScale是一款完全托管于亚马逊云科技,支持SQL的高效向量数据库。MyScale的优点是,它在提供与专用向量数据库相匹敌甚至优于的性能的同时,还支持完整的SQL语法。以下内容,将阐述MyScale是如何借助亚马逊云科技的基础设施,构建出一个稳定且高效的云数据库。
或许你尚未察觉,然而向量嵌入(vector embedding)实际上无处不在。它们构成了众多机器学习和深度学习算法的根基,被普遍的应用于从搜索引擎到智能助手等各式各样的应用。机器学习与深度学习通常会把文本、图像、音频、视频等非结构化数据转化为向量嵌入的形式进行储存,并借由向量相似性搜索技术进行语义相关性搜索。基于向量的相似性搜索现如今已被大量应用于各类人工智能驱动的应用场景,包括图像检索、视频分析、自然语言理解、推荐系统、定向广告、个性化搜索、智能客服以及欺诈检测等。在这样的背景下,对向量数据的管理显得很重要,我们需要能快速地储存、索引和搜索这些向量化的数据。
现存的向量数据库大体上可大致分为两大类别。一类是专为向量设计的专有向量数据库产品,例如Pinecone、Weaviate、Qdrant、Chroma、Milvus等。另一类则是在通用的SQL或NoSQL数据库产品上进行扩展,其中最为人熟知的SQL数据库之一Postgres通过插件pgvector支持了向量索引和搜索;而包括ClickHouse、Redis、Elasticsearch和Cassandra在内的许多开源数据库近期都增加了对向量索引的原生支持。
人们通常认为,专有的向量数据库专门为向量检索设计,可提供较佳的搜索性能。而支持向量搜索的通用数据库产品则依赖于原有的通用数据库,可提供更为完善的数据管理和结构化数据查询能力,向量检索性能则有所损失。MyScale基于开源的在线分析处理(OLAP)数据库ClickHouse开发,集成了自主研发的多尺度树图(英文:multi-scale tree graph,缩写MSTG)向量索引算法。它不仅继承了ClickHouse卓越的结构化数据分析和查询能力,同时也提供了数倍于专有向量数据库的性价比,从而将两者的优势集于一身,给公司可以提供了统一的结构化和非结构化数据管理方案。
MyScale是一款完全依托于亚马逊云科技云平台的数据库服务,其架构深度结合了亚马逊云科技的多元化产品线云端虚拟服务器、AWS EKS集群管理、AWS S3对象存储、AWS NLB负载均衡等。有赖于亚马逊云科技提供的强大底层设施,可迅速地构建出MyScale的云端服务产品。
如下图所示,MyScale云服务的架构设计包括全局控制平面(global control plane)、区域控制平面(regional control plane)以及区域数据平面(regional data plane)三个层次,每个层次对应一个Kubernetes集群。全局控制平面中部署了云服务的业务系统,负责组织、用户的管理及整体的使用量统计等。每个区域对应一个云服务供应商的一个可用区,如AWS US-EAST-1。每个区域独立部署一个控制平面和多个数据平面。控制平面提供该区域内的集群管理(创建、停止、销毁)API以及计费系统,数据平面则运行用户启动的MyScale数据库集群,它们运行在同一个数据平面中的多个可用区。
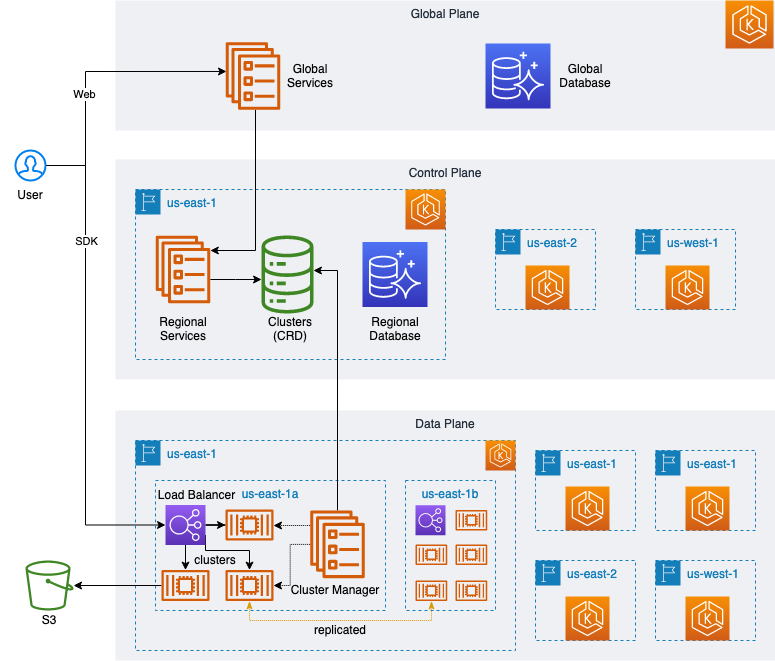
MyScale的所有服务都部署在亚马逊云科技的托管Kubernetes服务EKS上。EKS提供了高度可用、安全及可扩展的Kubernetes环境,这使得MyScale可以充分的利用Kubernetes的强大功能,如服务发现、负载均衡、自动扩缩容、安全隔离等。借助AWS EKS上的Cluster Autoscaler,MyScale能够准确的通过用户工作负载的需求,快速地启动、停止和扩展实例,对EKS的节点池进行扩缩容。
为了保证用户集群之间的隔离,MyScale利用了Kubernetes的命名空间(namespace)特性。在数据平面中,用户创建的每个MyScale数据库集群对应Kubernetes中的一个命名空间,这样就可最小化集群之间的相互影响。每个集群对应的命名空间中包含数据库节点、负载均衡服务和元数据存储服务。
用户在使用MyScale云服务时,能够最终靠运行在全局控制平面上的Web UI来创建和管理MyScale集群。用户在Web UI创建MyScale集群后,云服务的后端会调用相应区域控制平面中的接口,将MyScale数据库集群的具体参数和配置转成一个Kubernetes中的CRD资源配置文件,保存在该区域的控制平面中。对应的区域数据平面中运行的Cluster Manager会监听到区域控制平面中数据库集群CRD资源的变动情况,并做出相应的操作,在数据平面中创建或修改实际的MyScale数据库集群。在MyScale数据库集群启动后,用户都能够通过Web UI、Python/Java/NodeJS客户端、HTTP接口以及包括Langchain和LlamaIndex在内的LLM应用框架来访问MyScale数据库。
选择配备基于NVMe的本地SSD盘的EC2实例来部署MyScale数据库。和大部分选择纯内存HNSW向量索引算法的向量数据库不同,MyScale自研的MSTG算法允许将向量数据缓存在本地NVMe SSD盘中,因此MyScale在为用户提供高性能的向量搜索的同时,大大节约了内存的使用。在亚马逊云科技的公开测试中,MyScale超过了Pinecone、Weaviate、Qdrant、Zilliz等专有向量数据库,提供了最佳的性价比(QPS per dollar)。
在部署MyScale云服务时,可以使用Crossplane来实现对亚马逊云科技上的EC2和EKS服务的部署和管理。首先,通过Crossplane的AWS Provider配置了对应的亚马逊云科技账户信息,使得Crossplane能够访问和操作亚马逊云科技资源。然后,定义EC2和EKS的YAML配置文件,通过这些文件,可以定义需要的服务器和Kubernetes集群的参数,如实例类型、集群大小等。通过应用这些配置文件,Crossplane的AWS Provider会调用AWS API来创建和配置这些资源。
不仅如此,Crossplane还能够定期同步这些资源的状态,能够最终靠Kubernetes的接口来监控和管理这些资源。当需要修改或删除这些资源时,只需要修改对应的YAML文件并重新应用,Crossplane就会自动完成对应的操作。通过使用Crossplane,能够以一种声明式、统一和自动化的方式来管理云资源,大大提升工作效率和准确性。
在数据安全方面,MyScale采用了Teleport,一种先进的远程访问管理系统。Teleport能够为开发者和运维人员提供通过密文连接安全地访问Kubernetes集群的能力。这不仅提升了系统的安全性,也提升了操作的便捷性。更重要的是,Teleport具有全面的审计功能,能够详细记录所有会话和事件,这对于进行安全分析和满足合规性要求非常有帮助。这就意味着可以对任何操作有完全的可视化,从而更好地控制和保护MyScale云服务系统,为用户更好的提供安全可靠的服务。
这篇文章介绍了MyScale,一个在亚马逊云科技上托管的向量数据库。MyScale基于开源的在线分析处理(OLAP)数据库ClickHouse开发,集成了自主研发的多尺度树图(MSTG)向量索引算法,能够给大家提供优秀的数据管理和结构化数据查询能力,同时也提供了性价比突出的向量搜索功能,及结构化和非结构化联合分析、处理的功能,可以被大范围的应用于图像检索、视频分析、自然语言理解等AI驱动的场景。

