
机器学习即 ML,是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
机器学习作为人工智能研究较为年轻的分支,机器学习也分监督学习和非监督学习,同时随着人工智能慢慢的被人们重视和越热,深度学习也是机器学习的一个新的领域。
我们第一天学开车的时候一定不会直接上路,而是要你先学习基本的知识,然后再进行上车模拟。
只有对知识有全面的认知,才能确保在以后的工作中即使遇到了问题,也能够迅速定位问题所在,然后找方法去对应和解决。
所以我列了一个机器学习入门的知识清单,分别是机器学习的一般流程、十大算法、算法学习的三重境界,以此来开启我们的学习之旅。
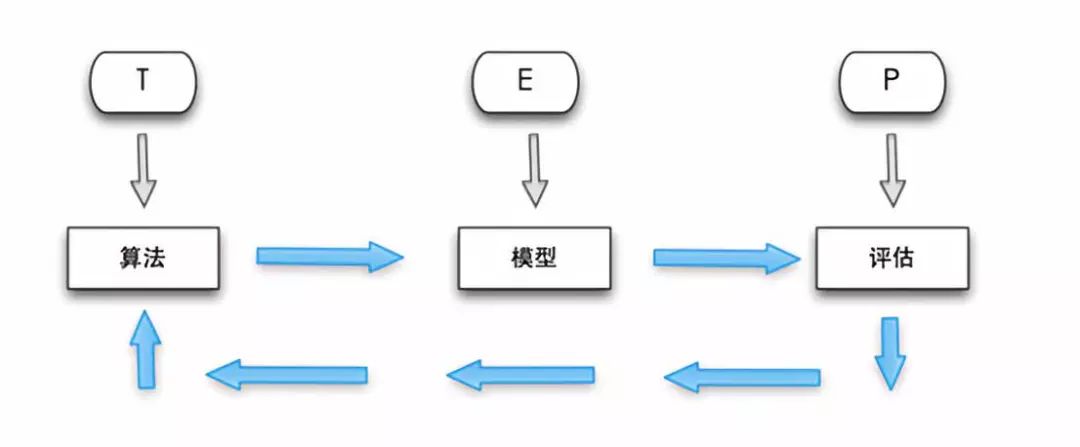
简单来说,机器学习就是针对现实问题,使用我们输入的数据对算法进行训练,算法在训练之后就会生成一个模型,这个模型就是对当前问题通过数据捕捉规律的描述。然后我们将模型进一步导入数据,或者引入新的数据集做评估,根据结果的好坏反过来调整算法,形成反馈和优化闭环。整一个完整的过程机器在不断的学习、训练和优化迭代,这个也是机器学习强大的地方。
为了进行机器学习和数据挖掘任务,数据科学家们提出了各种模型,在众多的数据挖掘模型中,国际权威的学术组织ICDM(the IEEE International Conference on Data Mining)评选出了十大经典的算法。
C4.5 算法是得票最高的算法,能够说是十大算法之首。C4.5 是决策树的算法,它创造性地在决策树构造过程中就进行了剪枝,并能处理连续的属性,也能对不完整的数据来进行处理。它可以说是决策树分类中,具有里程碑式意义的算法。
朴素贝叶斯模型是基于概率论的原理,它的思想是这样的:对于给出的未知物体想要进行分类,就需要求解在这个未知物体出现的条件下各个类别出现的概率,哪个最大,就认为这个未知物体属于哪个分类。
SVM 的中文叫支持向量机,英文是 SupportVector Machine,简称 SVM。SVM 在训练中建立了一个超平面的分类模型。
KNN 也叫 K 最近邻算法,英文是 K-Nearest Neighbor。所谓 K 近邻,就是每个样本都可以用它最接近的 K 个邻居来代表。如果一个样本,它的 K 个最接近的邻居都属于分类 A,那么这个样本也属于分类 A。
Adaboost 在训练中建立了一个联合的分类模型。boost 在英文中代表提升的意思,所以 Adaboost 是个构建分类器的提升算法。它可以让我们多个弱的分类器组成一个强的分类器,所以 Adaboost 也是一个常用的分类算法。
CART 代表分类和回归树,英文是 Classificationand Regression Trees。像英文一样,它构建了两棵树:一颗是分类树,另一个是回归树。和C4.5 一样,它是一个决策树学习方法。
Apriori 是一种挖掘关联规则(association rules)的算法,它通过挖掘频繁项集(frequentitem sets)来揭示物品之间的关联关系,被大范围的应用到商业挖掘和网络安全等领域中。频繁项集是指常常会出现在一起的物品的集合,关联规则暗示着两种物品之间有几率存在很强的关系。
K-Means 算法是一个聚类算法。你能这么理解,最终我想把物体划分成 K 类。假设每个类别里面,都有个“中心点”,即意见领袖,它是这个类别的核心。现在我有一个新点要归类,这时候就只要计算这个新点与K 个中心点的距离,距离哪个中心点近,就变成了哪个类别。
EM 算法也叫最大期望算法,是求参数的最大似然估计的一种方法。原理是这样的:假设我们想要评估参数 A 和参数 B,在开始状态下二者都是未知的,并且知道了 A 的信息就能够获得 B 的信息,反过来知道了 B 也就得到了 A。可优先考虑首先赋予A 某个初值,以此得到 B 的估值,然后从 B 的估值出发,重新估计 A 的取值,这样的一个过程一直持续到收敛为止。
PageRank 起源于论文影响力的计算方式,如果一篇文论被引入的次数越多,就代表这篇论文的影响力越强。同样 PageRank 被 Google 创造性地应用到了网页权重的计算中:当一个页面链出的页面越多,说明这个页面的“参考文献”越多,当这个页面被链入的频率越高,说明这个页面被引用的次数越高。基于这个原理,我们大家可以得到网站的权重划分。
算法可以说是机器学习的灵魂,也是最精华的部分。这 10 个经典算法在整个机器学习领域中的得票最高的,后面的一些其他算法也大多数都是在这个基础上进行改进和创新。今天你先对十大算法有一个初步的了解,你只需要做到心中有数就可以了。
第一重境界,将算法本身是做黑箱,在不知道算法具体原理的情况下能够掌握算法的基本应用情景(有监督、无监督),以及算法的基本使用情景,能够调包实现算法。
第二重境界则是能够进一步探索、掌握算法原理,并在此基础上明白算法实践过程中的关键技术、核心参数,最好能利用编程语言手动实现算法,能够解读算法执行结果,并在理解原理的基础上对通过调参对算法进行优化。
最后一重境界,实际上也是算法(研发)工程师的主要工作任务,即能够结合业务场景、自身数学基础来进行有明确的目的性的算法研发,此部分工作不仅需要扎实的算法基础原理知识,也需要扎实的编程能力。
今天我列了下学习机器学习你要掌握的知识清单,只有你对机器学习的流程、算法、原理有更深的理解,你才能在实际在做的工作中更好地运用,祝你在机器学习的路上越走越远。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。举报投诉

突破性技术峰会在北京召开,该峰会是全球最为著名的技术榜单之一,峰会围绕
突破性技术在中国落地性最强,并对目前最受关注的领域进行深入解读。2018年
科技,但科技依然拥有瞬间点燃人们激情的魔力。1月2日,阿里巴巴达摩院发布了“2019
科技趋势”,涵盖了智能城市、数字身份、无人驾驶、图神经网络系统、AI芯片、区块链、5G等
Pipfile.lock 文件,使你的构建更具确定性,避免产生难以查找的 Bug。2.PyTorchPyTorch是Facebook深度
框架,源于 Torch 框架,同时改善了 Torch 框架,基于ython
每一次比较都使搜索范围缩小一半。折半搜索每次把搜索区域减少一半,时间复杂度为Ο(logn) 。第五 BFPRT(线性查找
IBM具有开创性的工作开始于1997年在整个行业中采用铜线取代铝线进行布线,这一创新使电流阻抗立即下降了35%,同时芯片性能提高了15%。从此,IBM的科学家们一直沿着摩尔定律的轨道持续不断地推动性能的提升。以下是从IBM实验室过去
可用于一个特定的数据集(训练集)具有某一属性(标签),但是其他数据没标签或者需要预测标签的情况。无监督
上课时间安排:2022年05月27日 — 2022年05月30日No.1 第一天一、
编写1万行以上的项目,且能很好的把网游项目的规模控制在10万行代码以内。10. 桌面软件Python在图形界面开发上很强大,可以用tkinter/PyQT框架开发各种桌面软件!以上是Python
、谋发展的决定性手段,这使得这一过去为分析师和数学家所专属的研究领域越来越为人们所瞩目。本书第一部分主要介绍
”为主题的精选干货,今后每天一个主题为一期,希望对各位起到一定的帮助!(点击标题即可进入页面下载有关的资料)经典
) AlaphaGo与围棋界的较量,吸引了全世界的目光,也让大家见识到了
科技进展新闻新闻摘要:(1)思科收购邀约被拒,结果Datadog牛气独立IPO了(2)微软继续坐在了全球科学技术公司市值的“铁王座”上(3)全球数据中心大PK,少不了谷歌的欧洲计划(4)致敬
` 本帖最后由 gk320830 于 2015-3-4 14:11 编辑 世界
1. 决策树2. KNN3. KMEANS4. SVM5. 线性回归深度
1. BP2. GANs3. CNN4. LSTM应用人工智能基本概念数据集:训练集
(ML)的背景,它是什么,它是如何工作的,它为什么重要,以及 TinyML 是如何适应的
的分类是棘手的,有几种合理的分类,他们能够分为生成/识别,参数/非参数,监督/无监督等。 例如,Scikit-Learn的文档页面通过
由自变量(协变量、预测变量)和因变量(结果变量)组成,由一组自变量对因变量进行预测。通过这一些变量集合,我们
”这个词在中国有着非凡的魔力,凡事凡物只要跟它沾上边,必当“飞上枝头变凤凰”。即便恶人前面加“
有个常识性的认识,没有代码,没有复杂的理论推导,就是图解一下,知道这些
因素本文介绍的概念旨在加快示波器选择过程,帮助您避免某些常见的问题。不管您正在考虑的示波器来自哪家制造商,认真分析每个示波器与本文讨论的10个问题的关系,都将有利于客观地评估这些仪器。[hide][/hide]
的开发与性能提升,负责下述研究课题中的一项或多项,包括但不限于:人脸识别、检测、活体、跟踪、分类、语义分割、深度估计、图像处理
3.SVM 4.Apriori ,EM:最大期望值法,pagerank:是google
方法之一,Naive Bayes Cart:分类与回归。下面我将一一介绍
起源于人工智能,可以赋予计算机以传统编程所没办法实现的能力,比如飞行器的无人驾驶、人脸识别、计算机视觉和数据挖掘等。
无疑是当前数据分析领域的一个热点内容。很多人在平时的工作中都或多或少会用到
主要有三大类:1)分类;2)回归;3)聚类。今天我们重点探讨一下PCA
之一。PCA是Pearson在1901年提出的,后来由Hotelling在1933年加以发展提出的一种多变量的统计方法。
由自变量(协变量、预测变量)和因变量(结果变量)组成,由一组自变量对因变量进行预测。通过这一些变量集合,我们生成一个将输入映射到输出的函数。训练过程达到我们设定的损失阈值停止训练,也就是使模型达到我们应该的准确度等水平。
进行了改进:1)用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足。
的人都会被复杂的公式和晦涩难懂的术语吓到。但其实,如果有通俗易懂的图解,理解
的原理就会很容易。本文整理了一篇博客文章的内容,读者可依据这一些图理解看似高深的
模型”交替使用。这两个到底是一样的东西呢,还是不一样的东西?作为研发人员,你对排序
领域,有种说法叫做“世上没有免费的午餐”,简而言之,它是指没有一点一种
Top5 demi 在 周一, 04/01/2019 - 10:35 提交 本文将推荐五种
源自:AI知识干货 依据数据类型的不同,对一个问题的建模有不同的方式。在
,可能对于初学者来说,是相当不堪重负的。今天,我们将简要介绍 10 种最流行的
从数据中寻找一种相应的关系。 Iris 鸢尾花数据集是一个经典数据集,在统计
KNN(k-Nearest Neighbors)思想简单,应用的数学知识几乎为0,所以作为
翻译等领域中,相似性计算是必不可少的一项技术。在这些领域中,我们一般使用向量空间模型

