
开始被慢慢的变多的人关注,国外微软、苹果、谷歌、nuance,国内的科大讯飞、思必驰等厂商都在研发
我们都希望像《钢铁侠》中那样智能先进的语音助手,在与机器人进行语音交流时,让它听明白你在说什么。语音识别技术将人类这一曾经的梦想变成了现实。语音识别就好比“机器的听觉系统”,该技术让机器通过识别和理解,把语音信号转变为相应的文本或命令。
语音识别是以语音为研究对象,通过语音信号处理和模式识别让机器自动识别和理解人类口述的语言。语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。语音识别是一门涉及面很广的交叉学科,它与声学、语音学、语言学、信息理论、模式识别理论以及神经生物学等学科都有非常密切的关系。语音识别技术正逐步成为计算机信息处理技术中的关键技术,语音技术的应用慢慢的变成了一个具有竞争性的新兴高技术产业。
语音识别系统本质上是一种模式识别系统,包括特征提取、模式匹配、参考模式库等三个基本单元,它的基本结构如下图所示:
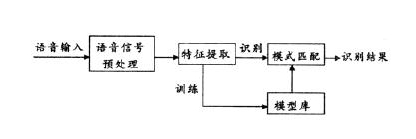
未知语音经过话筒变换成电信号后加在识别系统的输入端,首先经过预处理,再根据人的语音特点建立语音模型,对输入的语音信号做多元化的分析,并抽取所需的特征,在此基础上建立语音识别所需的模板。而计算机在识别过程中要根据语音识别的模型,将计算机中存放的语音模板与输入的语音信号的特征作比较,根据一定的搜索和匹配策略,找出一系列最优的与输入语音匹配的模板。然后根据此模板的定义,通过查表就能给出计算机的识别结果。显然,这种最优的结果与特征的选择、语音模型的好坏、模板是否准确都有直接的关系。
语音识别系统构建过程整体上包括两大部分:训练和识别。训练通常是离线完成的,对预先收集好的海量语音、语言数据库进行信号处理和知识挖掘,获取语音识别系统所需要的“声学模型”和“语言模型”;而识别过程通常是在线完成的,对用户实时的语音进行自动识别。识别过程通常又可大致分为“前端”和“后端”两大模块:“前端”模块主要的作用是进行端点检测(去除多余的静音和非说话声)、降噪、特征提取等;“后端”模块的作用是利用训练好的“声学模型”和“语言模型”对用户说话的特征向量进行统计模式识别(又称“解码”),得到其包含的文字信息,此外,后端模块还存在一个“自适应”的反馈模块,可以对用户的语音进行自学习,从而对“声学模型”和“语音模型”做必要的“校正”,进一步提升识别的准确率。
语音识别是模式识别的一个分支,又从属于信号处理科学领域,同时与语音学、语言学、数理统计及神经生物学等学科有非常密切的关系。语音识别的目的是让机器“听懂”人类口述的语言,包括了两方面的含义:其一是逐字逐句听懂非转化成书面语言文字;其二是对口述语言中所包含的要求或询问加以理解,做出正确响应,而不拘泥于所有词的正确转换。
自动语音识别技术有三个基础原理:首先语音信号中的语言信息是按照短时幅度谱的时间变化模式来编码;其次语音是可以阅读的,即它的声学信号可以在不考虑说话人试图传达的内容信息的情况下用数十个具有区别性的、离散的符号来表示;第三语音交互是一个认知过程,因而不能与语言的语法、语义和语用结构割裂开来。
语音识别系统的模型通常由声学模型和语言模型两部分所组成,分别对应于语音到音节概率的计算和音节到字概率的计算。声学建模;语言模型
连续语音识别中的搜索,就是寻找一个词模型序列以描述输入语音信号,从而得到词解码序列。搜索所依据的是对公式中的声学模型打分和语言模型打分。在实际使用中,往往要依据经验给语言模型加上一个高权重,并设置一个长词惩罚分数。
语音识别系统选择识别基元的要求是,有准确的定义,能得到足够数据来进行训练,具有一般性。英语一般会用上下文相关的音素建模,汉语的协同发音不如英语严重,能够使用音节建模。系统所需的训练数据大小与模型复杂度有关。模型设计得过于复杂以至于超出了所提供的训练数据的能力,会使得性能急剧下降。
听写机:大词汇量、非特定人、连续语音识别系统通常称为听写机。其架构就是建立在前述声学模型和语言模型基础上的HMM拓扑结构。训练时对每个基元用前向后向算法获得模型参数,识别时,将基元串接成词,词间加上静音模型并引入语言模型作为词间转移概率,形成循环结构,用Viterbi算法进行解码。针对汉语易于分割的特点,先进行分割再对每一段进行解码,是用以提高效率的一个简化方法。
对话系统:用于实现人机口语对话的系统称为对话系统。受目前技术所限,对话系统往往是面向一个狭窄领域、词汇量有限的系统,其题材有旅游查询、订票、数据库检索等等。其前端是一个语音识别器,识别产生的N-best候选或词候选网格,由语法分析器做多元化的分析获取语义信息,再由对话管理器确定应答信息,由语音合成器输出。由于目前的系统往往词汇量有限,也可以用提取关键词的方法来获取语义信息。
首先,我们大家都知道声音其实就是一种波。常见的mp3等格式都是压缩格式,必须转成非压缩的纯波形文件来处理,比如WindowsPCM文件,也就是俗称的wav文件。wav文件里存储的除了一个文件头以外,就是声音波形的一个个点了。下图是一个波形的示例。
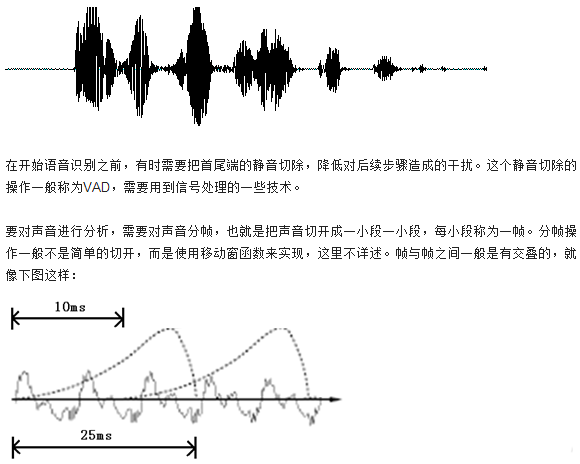
图中,每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。
分帧后,语音就变成了很多小段。但波形在时域上基本上没有描述能力,因此必须将波形作变换。常见的一种变换方法是提取MFCC特征,根据人耳的生理特性,把每一帧波形变成一个多维向量,可以简单地理解为这个向量包含了这帧语音的内容信息。这样的一个过程叫做声学特征提取。实际应用中,这一步有很多细节,声学特征也不止有MFCC这一种,具体这里不讲。
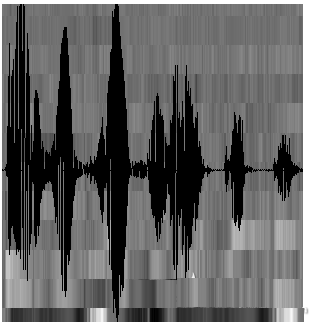
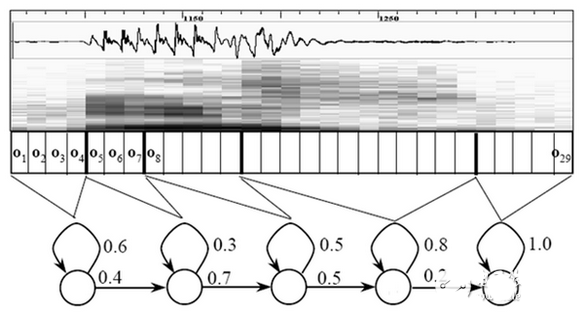
至此,声音就成了一个12行(假设声学特征是12维)、N列的一个矩阵,称之为观察序列,这里N为总帧数。观察序列如下图所示,图中,每一帧都用一个12维的向量表示,色块的颜色深浅表示向量值的大小。
音素:单词的发音由音素构成。对英语,一种常用的音素集是卡内基梅隆大学的一套由39个音素构成的音素集,参见TheCMUPronouncingDicTIonary?。汉语一般直接用全部声母和韵母作为音素集,另外汉语识别还分有调无调,不详述。
状态:这里理解成比音素更细致的语音单位就行啦。通常把一个音素划分成3个状态。
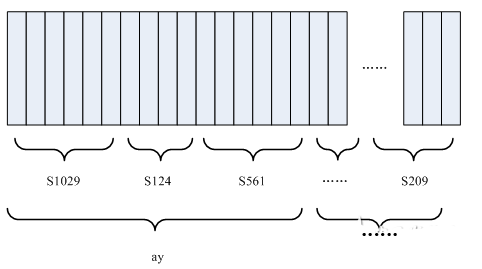
图中,每个小竖条代表一帧,若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词。也就是说,只要知道每帧语音对应哪个状态了,语音识别的结果也就出来了。
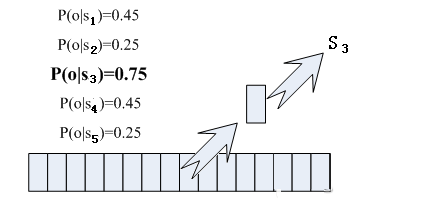
那每帧音素对应哪个状态呢?有个容易想到的办法,看某帧对应哪个状态的概率最大,那这帧就属于哪个状态。比如下面的示意图,这帧在状态S3上的条件概率最大,因此就猜这帧属于状态S3。
那这些用到的概率从哪里读取呢?有个叫“声学模型”的东西,里面存了一大堆参数,通过这一些参数,就不难得知帧和状态对应的概率。获取这一大堆参数的方法叫做“训练”,需要用巨大数量的语音数据,训练的方法较为繁琐,这里不讲。
但这样做有一个问题:每一帧都会得到一个状态号,最后整个语音就会得到一堆乱七八糟的状态号,相邻两帧间的状态号基本都不相同。假设语音有1000帧,每帧对应1个状态,每3个状态组合成一个音素,那么大概会组合成300个音素,但这段语音其实就没有这么多音素。如果真这么做,得到的状态号可能根本没办法组合成音素。实际上,相邻帧的状态应该大多数都是相同的才合理,因为每帧很短。
解决这样的一个问题的常用方法就是使用隐马尔可夫模型(HiddenMarkovModel,HMM)。这东西听起来好像很高深的样子,实际上用起来很简单:
这样就把结果限制在预先设定的网络中,避免了刚才说到的问题,当然也带来一个局限,比如你设定的网络里只包含了“今天晴天”和“今天下雨”两个句子的状态路径,那么不管说些什么,识别出的结果必然是这两个句子中的一句。
那如果想识别任意文本呢?把这个网络搭得足够大,包含任意文本的路径就可以了。但这个网络越大,想要达到比较好的识别准确率就越难。所以要根据实际任务的需求,合理选择网络大小和结构。
搭建状态网络,是由单词级网络展开成音素网络,再展开成状态网络。语音识别过程实际上的意思就是在状态网络中搜索一条最佳路径,语音对应这条路径的概率最大,这称之为“解码”。路径搜索的算法是一种动态规划剪枝的算法,称之为Viterbi算法,用于寻找全局最优路径。
其中,前两种概率从声学模型中获取,最后一种概率从语言模型中获取。语言模型是使用大量的文本训练出来的,可通过某门语言本身的统计规律来帮助提升识别正确率。语言模型很重要,如果不使用语言模型,当状态网络较大时,识别出的结果基本是一团乱麻。
⑥按照语义分析,给关键信息划分段落,取出所识别出的字词并连接起来,同时根据语句意思调整句子构成。
⑦结合语义,仔细分析上下文的相互联系,对当前正在处理的语句进行适当修正。
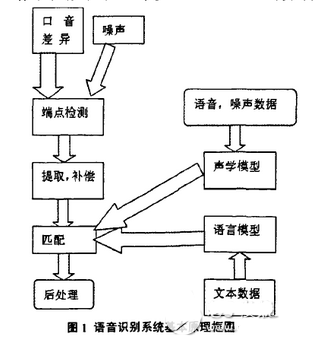
语音识别系统基础原理结构如图所示。语音识别原理有三点:①对语音信号中的语言信息编码是按照幅度谱的时间变化来进行;②由于语音是可以阅读的,也就是说声学信号可以在不考虑说话人说话传达的内容信息的前提下用多个具有区别性的、离散的符号来表示;③语音的交互是一个认知过程,所以一定不可以与语法、语义和用语规范等方面分裂开来。
预处理,其中就包括对语音信号进行采样、克服混叠滤波、去除部分由个体发音的差异和环境引起的噪声影响,此外还会考虑到语音识别基本单元的选取和端点检测问题。反复训练是在识别之前通过让说话人多次重复语音,从原始语音信号样本中去除冗余信息,保留关键信息,再按照一定规则对数据加以整理,构成模式库。再者是模式匹配,它是整个语音识别系统的核心部分,是根据一定规则以及计算输入特征与库存模式之间的相似度,进而判断出输入语音的意思。
前端处理,先对原始语音信号做处理,再进行特征提取,消除噪声和不同说话人的发音差异带来的影响,使处理后的信号能够更完整地反映语音的本质特征提取,消除噪声和不同说话人的发音差异带来的影响,使处理后的信号能够更完整地反映语音的本质特征。
早在计算机发明之前,自动语音识别的设想就已经被提上了议事日程,早期的声码器可被视作语音识别及合成的雏形。而1920年代生产的“RadioRex”玩具狗可能是最早的语音识别器,当这只狗的名字被呼唤的时候,它能够从底座上弹出来。最早的基于电子计算机的语音识别系统是由AT&T贝尔实验室开发的Audrey语音识别系统,它能够识别10个英文数字。其识别方法是跟踪语音中的共振峰。该系统得到了98%的正确率。到1950年代末,伦敦学院(ColledgeofLondon)的Denes已经将语法概率加入语音识别中。
语音识别技术的最重大突破是隐含马尔科夫模型HiddenMarkovModel的应用。从Baum提出相关数学推理,经过Labiner等人的研究,卡内基梅隆大学的李开复最终实现了第一个基于隐马尔科夫模型的大词汇量语音识别系统Sphinx。此后严格来说语音识别技术并没脱离HMM框架。
实验室语音识别研究的巨大突破产生于20世纪80年代末:人们终于在实验室突破了大词汇量、连续语音和非特定人这三大障碍,第一次把这三个特性都集成在一个系统中,很典型的是卡耐基梅隆大学(CarnegieMellonUniversity)的Sphinx系统,它是第一个高性能的非特定人、大词汇量连续语音识别系统。
这一时期,语音识别研究进一步走向深入,其显著特征是HMM模型和人工神经元网络(ANN)在语音识别中的成功应用。HMM模型的广泛应用应归功于AT&TBell实验室Rabiner等科学家的努力,他们把原本艰涩的HMM纯数学模型工程化,从而为更多研究者了解和认识,从而使统计方法成为了语音识别技术的主流。
20世纪90年代前期,许多著名的大公司如IBM、苹果、AT&T和NTT都对语音识别系统的实用化研究投以巨资。语音识别技术有一个很好的评估机制,那就是识别的准确率,而这项指标在20世纪90年代中后期实验室研究中得到了不断的提高。比较有代表性的系统有:IBM公司推出的ViaVoice和DragonSystem公司的NaturallySpeaking,Nuance公司的NuanceVoicePlatform语音平台,Microsoft的Whisper,Sun的VoiceTone等。

