
依据深度神经网络模型是机器学习最抢手的分支,在《人工智能选股--卷积神经网络(CNN)篇》咱们尝试用深度神经网络模型中的CNN模型进行选股,但是作用并不抱负。
除了由于未对模型进行充沛优化,还有一个或许的原因是这两个模型并不合适处理多因子表格数据,深度神经网络模型宗族中最合适处理表格数据的是TabNet,所以咱们接下来验证一下TabNet的选股作用。
TabNet是Google Cloud 在2019年提出的专门针对表格型数据规划的神经网络结构。深度学习在图画、文本和语音等数据处理上有了广泛的运用,但是关于常见的表格数据,XGBoost和LightGBM这类提高树模型依然是首选。
TabNet结合了树模型和DNN的优势。它运用一种称为次序谋事在人机制(Sequential Attention Mechanism)的办法完成了instance-wise的特征挑选,还经过encoder-decoder结构完成了自监督学习,以此来完成了高性能且可解释的表格数据深度学习架构。
下面让咱们经过TabNet的encoder和decoder结构看看它是怎样做到的。
TabNet选用次序多步架构,将输入从一个过程传递到另一过程。第i个过程输入来自第i-1个过程的处理信息来决议运用哪些特征,并输出处理后的特征标明以聚合到整体决议计划中。
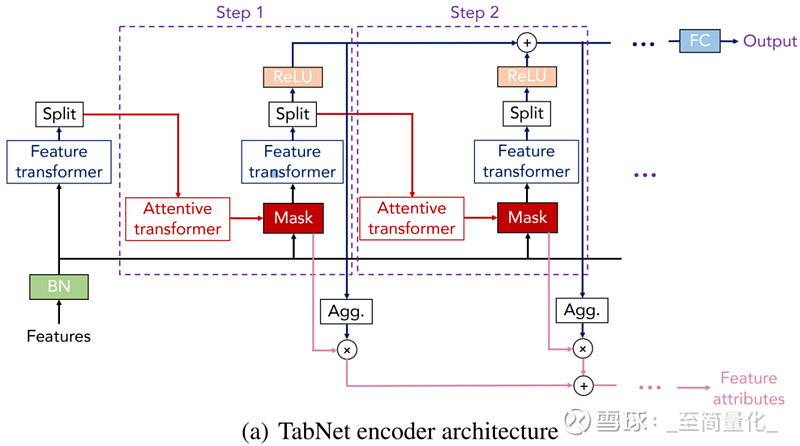
首先将特征输入BN(batch normalization层),而不需要对特征数据做大局标准化处理。
FC和BN无需介绍,Prior scales的作用是关于已经在之前的过程中运用了屡次的特征,削减它们的权重占比。Sparsemax经过将欧几里得投影映射到概率单纯形(simplex)来完成特征稀少化。
Mask可以理解为在当时过程对batch样本的谋事在人力权重分配,关于不同的样本,Attentive transformer层输出的谋事在人力权重也不同,这样的特征挑选被称为instance-wise特征挑选。
TabNet运用feature transformer处理挑选后的特征。Feature transformer模块由两个部分所组成,前半部分的参数是一切过程同享的,完成特征的共性处理;后半部分的参数是在每个过程上别离练习的,完成特征的特性处理。
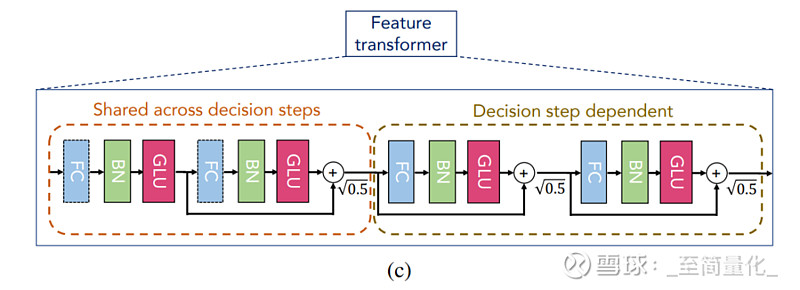
上图中的feature transformer前后两部分各有两个子模块,每个子模块由FC、BN和GLU(门控逻辑单元)组成,子模块之间用残差衔接,乘
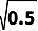
Feature transformer模块的输出被Split分红两部分,一部分经过Relu激活函数用于核算模型的终究输出,另一部分用来核算下一过程的Mask。
依据Google Cloud的论文,TabNet在多个表格数据集上的体现比肩乃至逾越了当时广为人知的许多树模型,例如LightGBM,更重要的是它将运用者从繁琐耗时的特征工程中摆脱出来。不过也有运用者标明人工做特征工程后再运用提高树模型可以到达的上限更高,这也是TabNet未能替代提高树的原因。
与XGBoost相同,TabNet既可用于回归问题,也可用于分类问题。接下来咱们选用与本系列其它篇相同的股票特征数据(详见《人工智能选股--线性回归和逻辑回归》)用TabNet进行涨跌分类猜测。
大败标明TabNet在运用默许参数的情况下取得了远超CNN的猜测作用,可见Google 针对表格数据做出的优化的确有作用。
在此基础上可以用前面讲过的超参数优化办法进一步骤优,也可以将TabNet的猜测成果与XGBoost的猜测成果组合运用,由于二者的猜测成果相关性很低,组合可以更好的起到不错的作用。
本篇是人工智能选股系列的第13篇。 依据深度神经网络模型是机器学习最抢手的分支,在《人工智能选股--卷积神经网络(CNN)篇》咱们尝试用深度神经网络模型中的CNN模型进行选股,但是作用并不抱负。除了由于未对模型进行充沛优化,还有一个或许的原因是这两个模型并不合适处理多因子表格...

