
理想汽车的智能驾驶技术主要依赖于端到端(E2E)和视觉语言模型(VLM)。这两种技术的结合,使得理想汽车在自动驾驶领域取得了显著的进展。
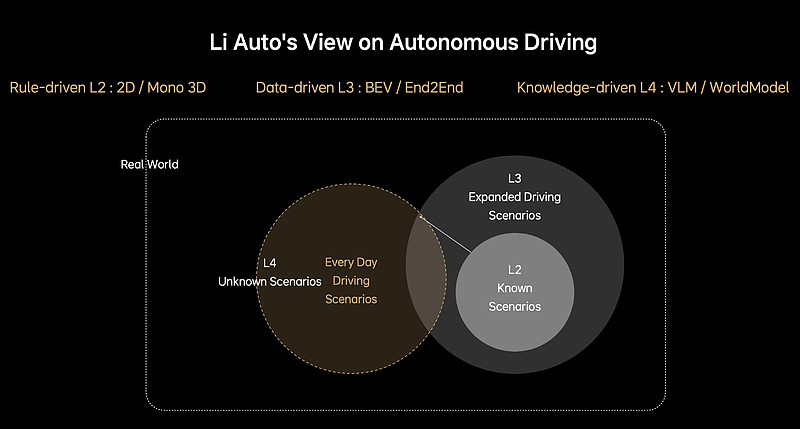
首先,端到端技术是一种数据驱动的方法,它通过直接从输入到输出的映射来处理复杂的场景,而不需要手动编写规则或进行大量的特征提取。这种办法能够有效地应对未知和变化多端的驾驶环境,提高无人驾驶系统的鲁棒性和适应能力。
其次,视觉语言模型(VLM)则利用深度学习技术来理解和解释图像中的内容。通过将视觉信息转化为语言描述,VLM能够更好地理解复杂的路况和交通环境,从而做出更加准确和及时的决策。例如,理想汽车引入了DriveVLM,这是一种结合了视觉理解和推理能力的无人驾驶系统,能够在各种复杂场景中表现出色。
理想汽车还通过优化其无人驾驶系统,将这些技术应用于实际车辆中。例如,他们开发了全国无图NOA系统,并通过300万clips训练出来的端到端+VLM监督型无人驾驶体系,以提升无人驾驶的性能和可靠性。
总结来说,理想汽车的E2E+VLM技术结合了端到端的数据驱动方法和视觉语言模型的强大视觉理解能力,为无人驾驶提供了一种高效、可靠且灵活的解决方案。这一技术的应用不仅提升了理想汽车自动驾驶系统的整体性能,也为未来自动驾驶技术的发展趋势提供了重要的参考。
理想汽车的端到端(E2E)技术是如何具体实现的,以及它怎么样处理和分析复杂场景中的数据?
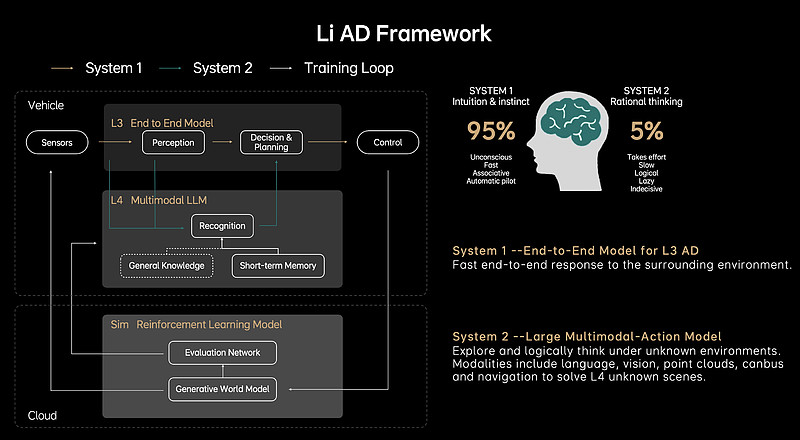
理想汽车的端到端(E2E)技术在智能驾驶领域的具体实现和数据处理分析方面,涵盖了多个关键环节和技术手段。
理想汽车的端到端模型覆盖了从感知到决策的整一个完整的过程。该模型通过集成多种传感器数据,实现对车辆四周环境的全面感知,并进行实时跟踪和预测,以做出准确的决策和规划。
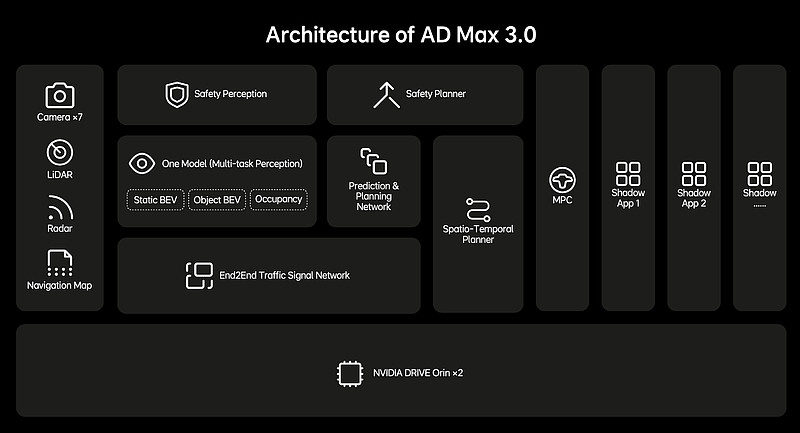
在AD Max 3.0和AD Pro 3.0平台上,理想汽车采用了大模型为主的端到端算法架构,从原先的多个小模型和人工规则为主的模块化算法架构,提升为更为高效和统一的大模型架构。
理想汽车使用Hadoop数据湖技术栈,结合Spark SQL和Impala,支持OLAP多维分析、定制报表和广告等业务需求。
在从Hadoop到云原生的演进过程中,理想汽车积累了丰富的一手经验,并在对象存储上使用JuiceFS,实现平台级文件共享和跨平台使用海量数据。
理想汽车通过YMatrix支持低延时的毫秒级数据入库,使得毫秒级的数据分析业务能够真正落地。
每天新增的车辆数据量达到2TB,通过Spark直接读写JuiceFS进行ETL(提取、转换、加载)加工。JuiceFS对HDFS API进行了完整兼容,简化了业务上的操作。

端到端模型的应用使得车辆可以在一定程度上完成全场景的无人驾驶,包括城市道路、红绿灯路口等复杂场景。
认知模型通过多模态大语言模型实现了对未知场景的理解和决策,逐渐增强了端到端模型的鲁棒性和适应性。

视觉语言模型(VLM)在无人驾驶系统中是如何工作的,特别是在理解和解释图像内容方面的技术细节是什么?
视觉语言模型(VLM)在无人驾驶系统中的应用大多分布在在理解和解释图像内容方面,具体技术细节如下:
VLM结合了图像和自然语言处理技术,能够同时处理图像和文本信息。这种多模态整合使得无人驾驶系统能够更全面地理解复杂的场景。
DriveVLM系统通过链式思考(Chain-of-Thought, CoT)模块来进行场景描述、场景分析和层次化规划。
VILA(Visual Language Model)采用了一系列创新的预训练方法和架构设计,以提升处理跨模态任务的能力。这包括多模态预训练,能够在复杂的视觉语言处理任务上达到更好的表现。
Mini-Gemini框架通过ConvNet架构生成更高分辨率的候选对象,增强视觉细节,同时保持大型语言模型的优势。
VLM增强的语义异常识别算法能更加进一步扩展到智能交通系统(ITS)中的灾害或紧急响应,提高交通系统的运营安全性和效率。
VLM的最大的目的是理解和解释图像与文本之间的关联,并根据图像生成相应的文本输出。
通过整合语言数据,车辆和交通系统能够深入理解现实环境,提高驾驶安全性和效率。
DriveVLM系统的具体功能和性能表现如何,与其他无人驾驶系统的比较结果是什么?
DriveVLM系统是一个结合了视觉大语言模型(VLM)和传统无人驾驶(AD)技术的混合系统,旨在提升无人驾驶的能力。具体来说,DriveVLM利用VLM的强大泛化和认知能力,实现了比传统模块更优越的性能。此外,DriveVLM-Dual通过与传统感知和规划模块的有选择互,提高了特征分析的精度。
该系统通过协同现有的3D感知和规划方法逐渐增强了这些能力,有效解决了VLMs固有的空间推理和计算挑战。DriveVLM-Dual还整合了链式思考(CoT)模块,用于场景描述、场景分析和层次化规划。
在性能表现方面,DriveVLM-Dual在nuScenes规划任务上取得了最先进的性能,这表明新方法虽然是为理解复杂场景而定制的,但在普通场景中也表现出色。此外,DriveVLM的设计使得它能不断吸收新的数据和知识,从而不断的提高自身的性能和表现。
与其他无人驾驶系统相比,DriveVLM和DriveVLM-Dual已经通过严格的评估证明了它们的有效性。例如,在nuScenes数据集上,作者采用位移误差(DE)和碰撞率(CR)作为指标来评估模型在不同场景中的表现。
全国无图NOA系统是如何结合端到端+VLM技术的,以及它在实际车辆上的应用效果如何?
全国无图NOA系统结合了端到端和VLM(Vision-Language Model)技术,通过大量的视频片段(Clips)进行训练,以实现高效、安全的无人驾驶体验。
理想汽车在推出全国无图NOA系统时,采用了300万片段的训练数据,并计划在未来推出超过1000万片段的训练数据,以逐步提升系统的性能。这种端到端+VLM的监督型无人驾驶体系可处理各种复杂的路况,提供更为可靠和安全的驾驶体验。
具体来说,端到端技术负责处理所有正常的无人驾驶任务,而VLM则用于解决兜底和泛化的问题,确保系统在遇到未知情况时仍能保持稳定。这种结合使得NOA系统不仅仅可以应对常见的驾驶场景,还能在遇到不正常的情况时有备无患。
在实际车辆上的应用效果也很出色。例如,长城汽车的无图城市NOA技术在保定复杂路况下表现出色,系统具备强大的适应性和可靠性,打破了对高精地图的依赖,实现了安全、高效的智能驾驶体验。此外,长城汽车的 Coffee Pilot Ultra 智驾系统支持无图全场景NOA,具备跨层记忆泊车、自动泊车、循迹倒车等功能,车位识别成功率达到98%,泊车成功率也达到了98%。

理想汽车在自动驾驶领域的其他关键技术进展和未来的发展趋势可以从多个角度进行详细分析。
理想汽车慢慢的开始使用英伟达最新一代的无人驾驶芯片Orin,这为其无人驾驶技术提供了强大的硬件支持。此外,理想汽车还与德赛西威深度合作,逐步提升其无人驾驶系统的性能。
理想汽车在端到端模型、大语言模型和视觉处理等方面也有显著进展。这些技术的应用使得理想汽车的自动驾驶系统更加智能和高效。
理想汽车自研了AEB(自动紧急制动)系统,并计划将其全部代码开源,以改善交通安全。此外,理想汽车还在2021款理想ONE车型上新增了NOA(导航辅助驾驶)功能,并提升了AEB性能,优化了摄像头和毫米波雷达探测融合能力。
理想汽车的智能驾驶总里程已超过5.1亿公里,其中高速NOA导航辅助驾驶里程达到了8789万公里。这表明理想汽车在实际道路条件下的自动驾驶技术已得到了广泛的测试和验证。
理想汽车计划在2025年实现L4级别的无人驾驶。这在某种程度上预示着理想汽车将在未来几年内推出能够完全自动化驾驶的车型。
理想汽车预计在2026年具备全自动驾驶能力。这将逐步提升其产品的竞争力和市场份额。
理想汽车计划在未来几年内加大对智能驾驶技术的研发投入,以提升其产品的核心竞争力。这包括增加研发资源、优化产品战略和拓展海外市场。
理想汽车将继续优化其新一代技术平台,以支持更高级别的无人驾驶技术。这将有利于理想汽车在智能驾驶领域保持领先地位。
理想汽车在自动驾驶领域已经取得了显著的技术进展,并且有明确的未来发展趋势。

