
人工智能自然语言处理领域的开放域问答技术在智能搜索、智能助手、智能客服等多个场景下,都发挥着及其重要的作用。特别是近些年,随着各种智能手机、智能音箱的普及,智能搜索快速进化,能够在一定程度上帮助用户在这些小屏和无屏设备上更快速、准确的获取有用信息。
近日,百度提出RocketQA,一种面向端到端问答的检索模型训练方法,助力机器问答理解技术迈出突破一步,推动了智能问答领域技术发展。该方法不仅在多个问答有关数据集中取得了当前最佳结果,同时也超越谷歌、微软、脸书、阿里、美团、卡内基梅隆大学、清华大学等企业和高校,问鼎微软MSMARCO数据集段落排序任务榜首。
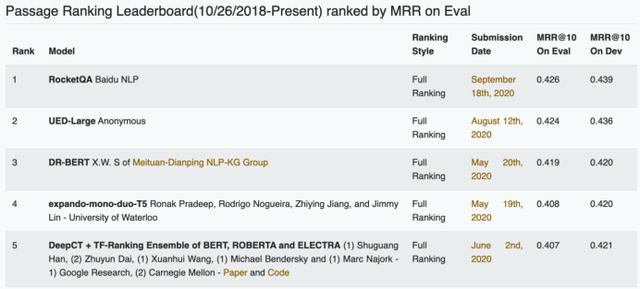
据了解,微软MSMARCO数据集是微软提出的大规模的面向问答的数据集,不仅规模大,而且贴近线万相关段落以及人工标注的问题答案。RocketQA在其中的脱颖而出,正显示了百度在模型检索能力方面的领先实力。
百度RocketQA训练方法是一种对偶式检索模型增强训练方法,并基于百度自研的语义理解技术与平台文心(ERNIE)进行训练,大幅度的提高了对偶式检索模型的效果。所谓对偶式检索模型,是一种区别于传统的检索模型的基于深度语义表示的模型,能利用强大的网络结构可以进行更深层次的学习,同时基于预训练语言模型,使语义理解更为丰富。然而在检索问答场景上,该模型的表现仍有欠缺,其训练任旧存在着,诸如训练场景和预测场景中样本数量差异较大、数据集中存在大量漏标注的正确答案、人工标注训练数据相对规模小成本大等问题和挑战。
针对对偶式检索模型训练中存在的问题和挑战,百度RocketQA通过跨批次负采样(cross-batch negatives)、去噪的强负例采样(denoised hard negative sampling)与数据增强(data augmentation)等3项技术,解决了以上问题和挑战,从而使得对偶式检索模型效果大幅度的提高。在实现RocketQA的过程中,这3项技术处于层层递进的关系,最终合成一套。同时,实现过程中还使用了百度文心(ERNIE)初始化模型参数。
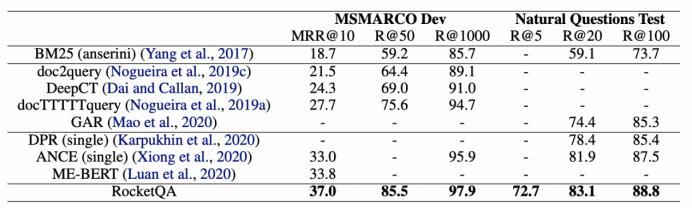
实验结果也显示,RocketQA在微软MSMARCO和谷歌Natural Question数据集的效果均大幅超过了已经发表的最好的检索模型。同时在答案抽取任务上,百度RocketQA检索结果的有效性也得以验证。
此外,百度RocketQA的提出,更代表着向实现“端到端问答”迈出的重要一步。不同于传统的级联式问答系统,“端到端问答”摒弃了传统系统中繁杂的构件,系统复杂性大幅度的降低,并且其中每个模块(段落检索和答案定位)都是可学习的,这样的设计能够让总系统实现端到端训练。从而能够基于用户实时的反馈实现在线训练,而不是只在封闭的数据集上闭门造车。正是基于上述优异性,端对端回答成为智能问答技术的发展的新趋势,甚至可能会引发问答系统的新一代技术变革。而百度RocketQA正是面向端对端回答方向,在优化解决对偶式检索模型训练中存在的,诸如训练、预测场景样本数量差异较大,人工标注规模小、成本高等问题之后,并取得MSMARCO榜首的好成绩,为“端对端回答”攻下一城。
实际上,在研发算法的过程中,高性能的并行训练也必不可少,它是研发人员快速尝试各种想法的利器。百度RocketQA的实现即完全基于飞桨深度学习框架。据相关资料显示,百度研究人员在使用飞桨分布式训练API(paddle.distributed.fleet)进行训练的同时,也采用了飞桨分布式训练扩展工具FleetX。前者是百度飞桨新API体系下的通用分布式训练API,其提供的经典数据并行训练方案能够大幅度的提高试验效率;后者是百度飞桨框架分布式训练扩展工具,提供数据分片并发下载、快速定义模型、快速提交集群任务等功能,可以在一定程度上完成了研发人员的使用效率的极大提升。
目前,RocketQA已逐步应用在百度搜索、广告等核心业务中,并将在更多场景中发挥作用。以百度搜索为例,可以感受一下问答技术在实际应用中对于使用者真实的体验的改变。比如,当我们在使用搜索引擎查询问题时,总是期望能第一时间得到更精准的回应。如果说传统的搜索总是给出可能的十条链接作为回答,那么,基于问答技术,问答结果得以优化,答案界面正在发生这样的变化:唯一的精准答案被直接给出,信息的获取更快速准确。
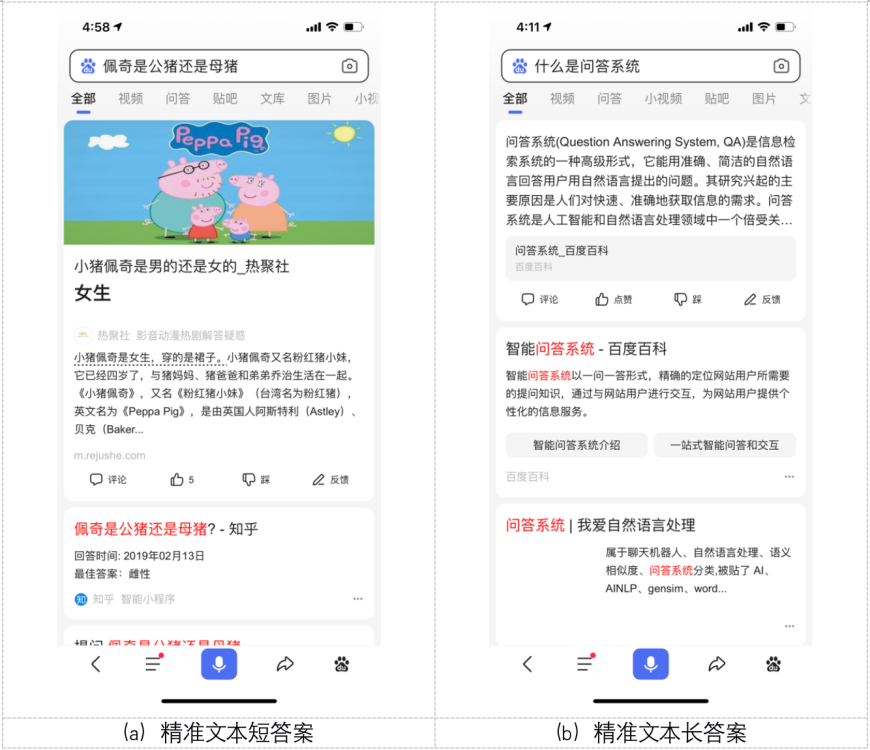
(百度搜索的TOP1结果:将问题的答案展现在搜索出来的结果的首位,提升用户体验)
正如上图所显示,当我们在百度搜索框输入诸如“佩奇是公猪还是母猪”的问题后,界面第一条即会已卡片形式直接给出“女生”的答案,第二条开始才是之前所熟悉的链接形式。这样一来,问与答之间的效率会大幅度的提高,用户能第一时间得到自己想要的答案,从而提升用户使用体验。在有了RocketQA的大规模应用后,百度搜索的TOP1结果会更好。

