
常见的机器学习算法是学习映射Y = f(X)来猜测新X的Y,这叫做猜测建模或猜测剖析,咱们的方针是尽可能作出最精确的猜测。 咱们不知道函数f的姿态或方法,假如知道的话,咱们将会直接用它,不需求用机器学习算法从数据中学习。

线性回归的表明是一个方程,它经过找到输入变量的特定权重(称为系数B),来描绘一条最适合表明输入变量x与输出变量y联系的直线。可能是计算学和机器学习中最闻名和最易了解的算法之一,猜测建模首要重视最小化模型差错或许尽可能作出最精确的猜测,以可解释性为价值。

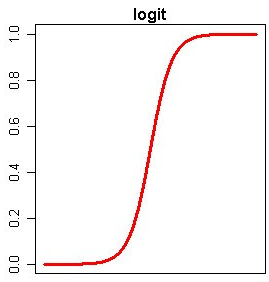
Logistic回归与线性回归类似,方针都是找到每个输入变量的权重,即系数值。与线性回归不同的是,Logistic回归对输出的猜测运用被称为 logistic 函数的非线性函数进行改换。 它是一个快速的学习模型,而且关于二分类问题十分有用。
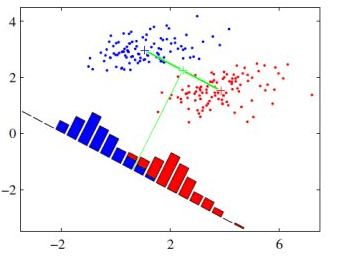
线性判别剖析进行猜测的办法是核算每个类别的判别值,并对具有最大值的类别进行猜测。该技能假定数据呈高斯分布,因而最好预先从数据中删除异常值。这是处理分类猜测建模问题的一种简略而强壮的办法。
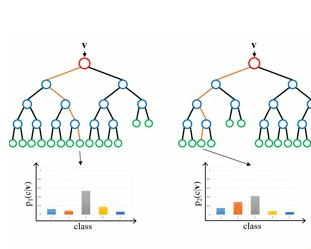
决策树的叶节点包括一个用于猜测的输出变量y,经过遍历该树的切割点,直到抵达一个叶节点并输出该节点的类别值就能够作出猜测。决策树模型的表明是一个二叉树,学习速度和猜测速度都很快,能处理很多问题,而且不需求对数据做特别预备。
朴素贝叶斯是一个简略可是很强壮的猜测建模算法,该模型由两种概率组成,这两种概率都能够直接从练习数据中核算出来:1)每个类别的概率;2)给定每个x的值,每个类别的条件概率。假如数据是实值时,一般假定一个高斯分布,这样做才能够简略的估量这些概率。
KNN 算法在整个练习会集查找K个最类似实例(近邻)并汇总这 K 个实例的输出变量,以猜测新数据点。KNN需求很多内存或空间来存储一切数据,可是只要在需求猜测时才履行核算(或学习)。能够每时每刻更新和办理练习实例,以坚持猜测的精确性。
学习向量量化(简称 LVQ)是一种人工神经网络算法,它答应你挑选练习实例的数量,并精确地学习这些实例应该是怎样的。在学习之后,最类似的近邻经过核算每个码本向量和新数据实例之间的距离找到。然后回来最佳匹配单元的类别值作为猜测。
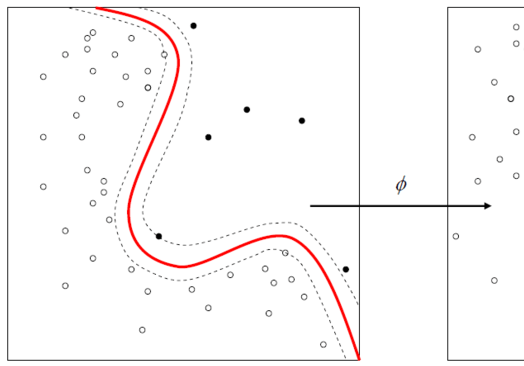
超平面是切割输入变量空间的一条线,超平面和最近的数据点之间的距离被称为距离,分隔两个类别的最好的或最理想的超平面具有最大距离。实际上,优化算法用于寻觅最大化距离的系数的值。
Bagging 是从数据样本中预算数量的一种强壮的计算办法。在练习数据中抽取多个样本,然后对每个数据样本建模。当你需求对新数据来进行猜测时,每个模型都进行猜测,并将一切的猜测值均匀以便更好的估量实在的输出值。
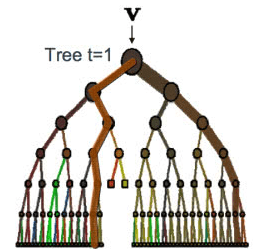
随机森林是对Bagging办法的一种调整,在随机森林的办法中决策树被创立以便于经过引进随机性来进行次优切割,而不是挑选最佳切割点。针对每个数据样本创立的模型将会与其他方法得到的不一样,能够越来越好的估量实在的输出值。回来搜狐,检查更加多

